Continuous Integration (Part 3) – CI Best Practices
This post was originally written for TechTownTraining blog. You can find the original article here
Introduction
This is Part 3 in the series on Continuous Integration. In this article, we will go through the best practices of implementing a CI process. I’ll also cover some real world tips and warnings based on my experiences in the industry.
A quick recap: In Part 1 of this series, we covered the basic concepts of CI and its relevance in an Agile and DevOps team culture. In Part 2, we introduced what a CI Server is and how it can seamlessly bring together various industry standard practices of implementing a CI process.
If you haven’t yet read the previous posts, I highly recommend glancing through them before you continue with this one!
Martin Fowler, in his white paper on CI, mentioned key practices that should be part of any CI setup. These recommendations have become “THE” set of Continuous Integration best practices over the years. The Wikipedia page on the same topic provides an essence of the principles set forth by Martin Fowler.
We’ll take a look at each of the best practices along with insights of my own.
Best Practices
1. Maintain a Single Source Repository.
“This practice advocates the use of a revision control system for the project’s source code. All artifacts required to build the project should be placed in the repository. In this practice and in the revision control community, the convention is that the system should be buildable from a fresh checkout and not require additional dependencies. Extreme Programming advocate Martin Fowler also mentions that where branching is supported by tools, its use should be minimised. Instead, it is preferred for changes to be integrated rather than for multiple versions of the software to be maintained simultaneously. The mainline (or trunk) should be the place for the working version of the software.”
Good Practices
- This principle is not to be taken literally, it does not mean that you only need to have one single repository. The key take away here is to have all artifacts needed to build the project in one repository. The project should be buildable from a fresh checkout and not require additional dependencies or manual steps.
- The definition of ‘project’ here is up to you, it could mean the entire shippable product if your codebase is small or could be any of the logical modules or components into which your code has been organized.
Caution
The original principle recommends NOT to use branching in the version control system. Instead, it recommends that only a single branch of the project be under development all the time.
I, however, disagree with it. In most organizations, it is necessary to have many branches where development is ongoing in parallel. Often, companies need to support the previous releases of the product, fix bugs in them, while other team members start working on the next release. This requires multiple branches in the code base.
2. Automate the build
“A single command should have the capability of building the system. Many build tools, such as make, have existed for many years. Other more recent tools are frequently used in continuous integration environments. Automation of the build should include automating the integration, which often includes deployment into a production-like environment. In many cases, the build script not only compiles binaries, but also generates documentation, website pages, statistics and distribution media (such as Debian DEB, Red Hat RPM or Windows MSI files).”
Good Practices
-
Automation of the build should include steps such as compiling the code, executing unit tests and integration tests. They may also include a number of other tools as described in the previous post – code quality checks, semantic checks, measuring technical debt etc.
Most of the modern build tools support these additional integrations and should be used in developing continuous integration environments.
-
In the real world projects, different teams might be responsible for developing different parts of the system, each having its own repository. In such a case, it is almost impossible (without significant work) and quite un-necessary to automate the build across the entire product. It is generally sufficient if the build automation is developed for each individual part of the system.
Caution
- Define the purpose of the CI Process i.e. is there a point to investing in CI other than automating the build process? What metrics are you planning to measure as part of the CI process? Very often, I see that the CI setup is seen as a developer’s tool alone.
- Extending on the previous point, CI is not Agile/DevOps, it’s only one of the tools used in implementing a successful CI process for your entire organization. The Agile/DevOps paradigm extends way beyond the technical aspects of software development and into the culture of the organization.
3. Make the build self-testing
“Once the code is built, all tests should run to confirm that it behaves as the developers expect it to behave.”
Good Practices
- The code should contain unit tests at the minimum. Frameworks such as JUnit can be used to easily mock dependencies.
- The interactions of a particular component with other modules should be mocked. This ensures that a module can be tested independently of others.
Caution
-
Unit tests should test behavior, not implementation details.
What is the difference? Let’s take an example to figure it out:
Testing for behavior: “I don’t care how you calculate the speed of the car, just make sure that the answer is correct”
When I test for implementation: “I don’t care what the answer is, just make sure you use the equation: Speed = Distance/Time”
Testing for behavior is the correct approach because we need to verify the results, not how the solution was achieved.
-
Many testing frameworks allow us to Assert the mock objects i.e. test whether the mock object was called, whether it was passed in a certain argument etc. These assets should be minimized, unless testing for the implementation itself is the primary concern.
4. Everyone commits to the baseline every day
“By committing regularly, every committer can reduce the number of conflicting changes. Checking in a week’s worth of work runs the risk of conflicting with other features and can be very difficult to resolve. Early, small conflicts in an area of the system cause team members to communicate about the change they are making. Committing all changes at least once a day (once per feature built) is generally considered part of the definition of Continuous Integration. In addition performing a nightly build is generally recommended.] These are lower bounds; the typical frequency is expected to be much higher.”
Good Practices
- The code should contain unit tests at the minimum. Frameworks such as JUnit can be used to easily mock dependencies.
- The interactions of a particular component with other modules should be mocked.
Caution
-
No in-progress work should be committed into the master branch. The master branch should always be working software.
-
Do not commit to any branch if you see that the build is broken.You should verify what caused the error, and try to solve it as soon as possible instead of committing your code.
Why shouldn’t you check-in when the build is broken?
First of all, your own commit might have some problems, it might have broken an expected behavior. You won’t know what those problems are unless you knew the state of the build on the previous check-in. Every time you check-in, you can be compounding the problem by adding to the existing errors.
5. Every commit (to baseline) should be built
“The system should build commits to the current working version to verify that they integrate correctly. A common practice is to use Automated Continuous Integration, although this may be done manually. For many, continuous integration is synonymous with using Automated Continuous Integration where a continuous integration server or daemon monitors the revision control system for changes, then automatically runs the build process.”
Good Practices
-
You should separate the CI workflows for the master branch and other branches. This includes the steps from compilation right up to packaging and testing.
The build on the master branch should generally include more tests. The build on the master branch might also need different scripts to run because the application might need to be packaged differently for different deployment platforms. A build running on the other branches might not need a packaging step at all, or it is generally limited to packaging for the same platform as that of the developer.
-
A “nightly build” should also execute at a scheduled time every night. This build should include more verifications than the ones on other branches. It takes longer to run and is executed less frequently.
Caution
- There should be no commented out tests in the mainline branch. By commenting out tests, we get an incorrect indication of the status of the build.
- Introduce coding standard checks as part of CI process. The code has to be reviewed using the automated tools as well as by the team members before check-in to mainline.
6. Keep the build fast
“The build needs to complete rapidly, so that if there is a problem with integration, it is quickly identified.”
Good Practices
- The test pyramid, as explained by Martin Fowler is depicted below. You should aim to have faster-executing tests than slow tests. This would mean that you need to have more unit tests than other types of tests.
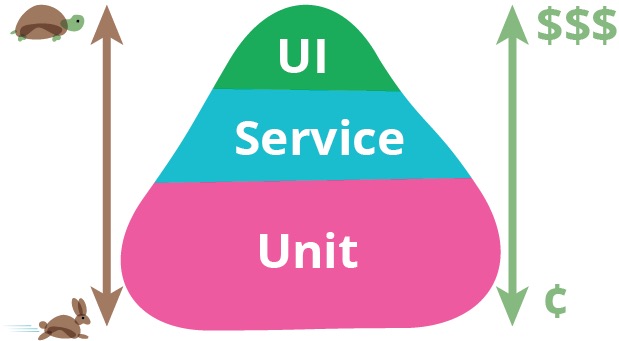
Image source: MartinFowler.com
- Avoid using a database in unit tests. If possible avoid using it for integration tests too. This usually needs the integration tests to use an alternative data source, usually pointing to an in-memory database. If it’s not possible to avoid using a real database for tests, you need to make sure to refresh the database before each test, so as to ensure that the data is in a known state, and tests don’t start with inconsistent data.
Caution
Do not depend on a large number of UI tests, UI tests are brittle i.e. they frequently change and need a lot of maintenance. I recommend you use UI test frameworks like Selenium to alleviate some of the problems of UI testing such as a location of the UI element changing on the screen, handling UI events etc.
7. Test in a clone of the production environment
“Having a test environment can lead to failures in tested systems when they deploy in the production environment because the production environment may differ from the test environment in a significant way. However, building a replica of a production environment is cost prohibitive. Instead, the test environment, or a separate pre-production environment (“staging”) should be built to be a scalable version of the actual production environment to both alleviate costs while maintaining technology stack composition and nuances. Within these test environments, service virtualisation is commonly used to obtain on-demand access to dependencies (e.g., APIs, third-party applications, services, mainframes, etc.) that are beyond the team’s control, still evolving, or too complex to configure in a virtual test lab.”
Good Practices
This is the hardest principle to put into practice in real world development. This needs the build automation system to create and deploy the packages into a staging environment that reflects the real production environment. Unless your application is self-sufficient with no external dependencies, achieving this is difficult because of the sheer complexity of the production environment.
My suggestion for complex products is to invest time and effort into using a virtualization platform or a container platform such as Docker to replicate the production environment. Continuous Delivery pipelines can be used to deploy the build into these environments.
8. Make it easy to get the latest deliverables
“Making builds readily available to stakeholders and testers can reduce the amount of rework necessary when rebuilding a feature that doesn’t meet requirements. Additionally, early testing reduces the chances that defects survive until deployment. Finding errors earlier also, in some cases, reduces the amount of work necessary to resolve them. All programmers should start the day by updating the project from the repository. That way, they will all stay up to date.”
Good Practices
It is recommended to use an artifact repository such as Nexus to store the packages from the latest build. Usually, the packages stored in such an artifact repositories are also version controlled with a build number. This makes it easy for everyone involved to get any artifacts, current or past.
Caution
Only the build packages from the mainline branch should be stored on the artifact repository. If not, it will result in overwriting of the existing packages each time someone builds a work in progress branch.
9. Everyone can see the results of the latest build
“It should be easy to find out whether the build breaks and, if so, who made the relevant change.”
Good Practices
- All modern CI servers have the capability to display a dashboard containing the status of the builds. They can also be configured to show other metrics as described in the previous post.
- All CI servers can also be configured to send email notifications when the build completes. It is recommended that the emails are sent to the whole team when the build fails so that it can be fixed as soon as possible.
Caution
- A failing build is not a hall of shame. Everyone makes mistakes and developers are not immune to it. When the build is failing, it should be considered as a welcome result because the problem was identified early. Failing early and fixing problems early is the key aim of CI.
- CI is not only for developers. The various metrics that can be derived using the CI system by installing extensions can be made use of to improve not just the quality of the software, but also the quality of the development practices.
10. Automate deployment
“Most CI systems allow the running of scripts after a build finishes. In most situations, it is possible to write a script to deploy the application to a live test server that everyone can look at. A further advance in this way of thinking is continuous deployment, which calls for the software to be deployed directly into production, often with additional automation to prevent defects or regressions.”
Caution
-
Not all projects need automated deployment, especially if the enterprise servers are on customer site. The project plan determines when the upgrade to the latest build happens on the customer site, usually, this is planned months in advance.
If the production sites are self-hosted by the same company that is developing the software, it is much more beneficial to invest in Continuous deployment systems. Continuous deployment is the next logical step after the process for Continuous integration is in place and working well.
-
Not all commits result in a shippable product. It is a common misconception in the Agile community that each build is a shippable product. A shippable product is entirely different than working software!
Summary
I hope this information gave you an insight into some of the best practices to improve the implementation of your CI process. CI plays a significant role in streamlining the software development process. Fine tuning the CI practices will result in increased overall efficiency and agility of your software development process. Combining these best practices is the best way to deliver software of great quality with quicker time to market!